关于AVAILABILITY_MODE
需要注意的是,与Oracle Data Guard不尽相同的概念是,在Always On AG中每个replica上都可以设置自己的AVAILABILITY_MODE。
AVAILABILITY_MODE参数有三个可选值,分别是SYNCHRONOUS_COMMIT、ASYNCHRONOUS_COMMIT和CONFIGURATION_ONLY。
- SYNCHRONOUS_COMMIT:同步提交,意味着主replica的事务必须等到备replica将变更日志写入磁盘中才可以提交。可以设置包括主replica在内的最多三个replica处于同步提交状态。
- ASYNCHRONOUS_COMMIT:异步提交,意味着replica无需等待备replica的动作而可以直接提交成功。
- CONFIGURATION_ONLY:仅同步AG配置元数据。设置为该值的replica仅会从主replica中将AF配置的元数据同步过来,不会同步任何用户表数据。
在一个多节点replica的AG环境中,如果:
- 主库和其中任何一个备库设置为SYNCHRONOUS_COMMIT,则主库的日志提交必须等待该备库完成日志写入;
- 主库设置为SYNCHRONOUS_COMMIT,而所有备库都设置为ASYNCHRONOUS_COMMIT,则主库无需等待;
- 主库设置为ASYNCHRONOUS_COMMIT,则无视备库上该参数的设置,主库均无需等待。
在多节点的AG环境中,假设一个主库配置了两个同步的secondary,那么是不是要等待这两个secondary都完成日志写入才能提交事务呢?此时又引入了required_synchronized_secondaries_to_commit参数。
关于required_synchronized_secondaries_to_commit
required_synchronized_secondaries_to_commit参数是在SQL Server 2017中引入的,这个参数从直观意义上就可以看得出是指定当commit的时候需要有个几个同步的secondary replica存活。
这个参数在三节点的AG集群中,默认值为1,也就是如果至少要存活一个secondary replica,主库上的事务才可以提交,否则commit就会一直等待。这很好理解。
但是不好理解的是,该参数可以手工修改为0,从字面上看应该是说,即使所有secondary replica都不同步了,也是可以允许commit的。
但是实际情况却并非如此,修改为0是不起作用的。通过以下测试可以知道。
首先,设置required_synchronized_secondaries_to_commit参数为0
[shell] sudo pcs resource update ag_cluster required_synchronized_secondaries_to_commit=0 [/shell] [sql] [Kamus@centos1 ~]$ sql 1> select name,required_synchronized_secondaries_to_commit from sys.availability_groups; 2> GO name required_synchronized_secondaries_to_commit —————————— ——————————————- ag1 0 (1 rows affected) [/sql]现在三个节点都是正常状态。
[sql] 1> select r.replica_server_name,r.availability_mode_desc,r.session_timeout ,rs.connected_state_desc 2> from sys.availability_replicas r,sys.dm_hadr_availability_replica_states rs 3> where r.replica_id=rs.replica_id; 4> GO replica_server_name availability_mode_desc session_timeout connected_state_desc —————————— —————————— ————— —————————— centos1 SYNCHRONOUS_COMMIT 10 CONNECTED centos2 SYNCHRONOUS_COMMIT 10 CONNECTED centos3 SYNCHRONOUS_COMMIT 10 CONNECTED (3 rows affected) [/sql]在主节点上进行Insert,可以成功,这很好。
[sql] 1> insert into t1 select * from sys.databases; 2> GO (6 rows affected) [/sql]停掉一个secodary replica。显示第二个节点已经DISCONNECTED。
[sql] 1> select r.replica_server_name,r.availability_mode_desc,r.session_timeout ,rs.connected_state_desc 2> from sys.availability_replicas r,sys.dm_hadr_availability_replica_states rs 3> where r.replica_id=rs.replica_id; 4> GO replica_server_name availability_mode_desc session_timeout connected_state_desc —————————— —————————— ————— —————————— centos1 SYNCHRONOUS_COMMIT 10 CONNECTED centos2 SYNCHRONOUS_COMMIT 10 DISCONNECTED centos3 SYNCHRONOUS_COMMIT 10 CONNECTED (3 rows affected) [/sql]在主库上进行Insert,还是可以成功,这很好。
[sql] 1> insert into t1 select * from sys.databases; 2> GO (6 rows affected)[/sql]再停掉一个secodary replica。显示2、3节点都已经DISCONNECTED。
[sql] 1> select r.replica_server_name,r.availability_mode_desc,r.session_timeout ,rs.connected_state_desc 2> from sys.availability_replicas r,sys.dm_hadr_availability_replica_states rs 3> where r.replica_id=rs.replica_id; 4> GO replica_server_name availability_mode_desc session_timeout connected_state_desc —————————— —————————— ————— —————————— centos1 SYNCHRONOUS_COMMIT 10 CONNECTED centos2 SYNCHRONOUS_COMMIT 10 DISCONNECTED centos3 SYNCHRONOUS_COMMIT 10 DISCONNECTED (3 rows affected) [/sql]在主库上执行Insert,此时hang住,这很不好。
[sql] 1> insert into t1 select * from sys.databases; 2> GO [/sql]更讨厌的是,对于该表的查询也会hang住,这就更不好了。
[sql] 2> select count(*) from t1; 3> GO [/sql]现在数据库中的等待是什么呢?确实是HADR_SYNC_COMMIT。
[sql] 1> select STATUS,COMMAND,DATABASE_ID,WAIT_TYPE,WAIT_TIME from sys.dm_exec_requests where command=’INSERT’; 2> GO STATUS COMMAND DATABASE_ID WAIT_TYPE WAIT_TIME —————————— —————————— ———– —————————— ———– suspended INSERT 5 HADR_SYNC_COMMIT 1670 (1 rows affected) [/sql]如果我们更进一步做一个session的xevent trace,可以看到等待的是WaitForHarden,而Harden的意思即是remote replica的日志写入。现在主库在等待一个备库的日志完成写入,然后自己才能提交成功。在正常情况下,当主库不再需要等待备库而可以自行commit的情况下,在xevent trace中应该出现将备库的commit_policy标志为donothing状态,也就是在xevent中应该要出现hadr_db_partner_set_policy事件才是正常的,然而这里并没有出现。
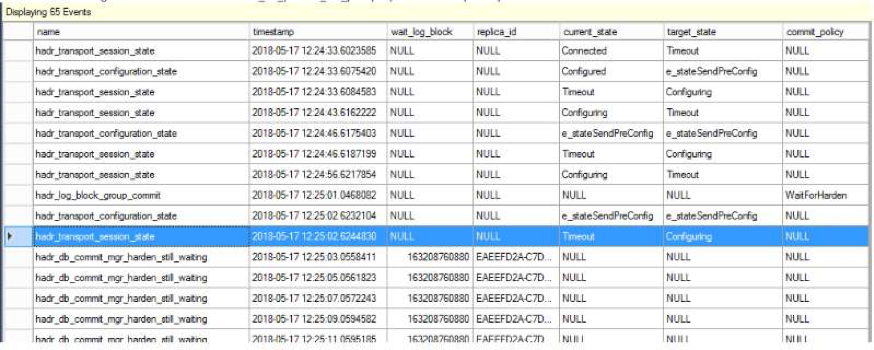
但是我们明明把required_synchronized_secondaries_to_commit参数设置为0了,这很违反常识,不是吗?
结论
在SQL on Linux中如果设置了availability_mode为SYNCHRONOUS_COMMIT,那么必须至少有一个secondary replica(或者一个config node)是存活的,否则priamry replica中就不再允许任DML操作,而尝试对于某表进行DML之后,还会进一步阻塞对于该表的查询。即使设置了required_synchronized_secondaries_to_commit=0也是无效的。也许微软需要更新一下文档,明确说明在多个sync的secondary存在的情况下,该参数即使修改为0也仍然按照1来处理。
这是一个很奇怪的design,因为这强制去掉了当一个集群中所有备库都崩溃时,主库能够自动转为异步提交模式的功能,从而造成了所有备库失效则会影响主库业务正常进行这样一个大问题。
实际上这个design是在SQL on Linux 2017 CU1之后才修改的,在CU1之前还是允许当所有备库都失效以后,主库仍然是可以正常读写的。甚至在现在的文档中仍然保留了这样的描述。

以上文档描述来自:High availability and data protection for availability group configurations
这意味着在SQL Server 2017 CU 1之后,不再支持单纯的read-scale功能的AG了。虽然不太理解微软的SQL Server程序员是怎么考虑这个问题的,但是现状就是如此。
相比起Oracle的Data Guard而言,也就是现在SQL Server的AG只有同步(等同于DG的Maximum protection),异步(等同于DG的Maximum performance)这样两种方式,而缺少了DG的Maximum availability模式。
我只能认为这是一个设计理念的问题,微软的程序员更倾向于关注数据一致性,但是我期望在未来SQL Server可以对此进行改进。